
Getting Organizational Data Ready for Machine Learning and AI
On the journey toward digital transformation, every company wants to leverage machine learning (ML) and artificial intelligence (AI). Yet many overlook one simple truth: AI is only as smart as your data is ready.
Before you can build models or deploy AI solutions, your organization needs to prepare its data foundation — a process often referred to as “data readiness.”
“Data Readiness”: Definition and Context
On the most basic level we mean having data across an enterprise that is ready for integration because it is “clean”, consistent, and in places and formats that are easily accessible by machine learning and AI.
The great news is that data readiness projects might be done for AI and Machine Learning purposes, however, they serve the entire organization’s efficiency and profitability. All the way down to groups still using basic reports in Excel…
Which might sound basic, but
that’s a lot of information and
it can be hard, and expensive, to do.
To that end, we have learned that a clear and non-technical understanding/layout for management can be very helpful in planning for the effort and disruption of successful data projects.
Here’s a high-level overview, remembering the term AI has been around since the 1956 Dartmouth Conference, and nothing here is exactly new: it’s the speed and accessibility of development that is notable.
Implementing Data Readiness
Getting organizational data ready means transforming raw, scattered, and inconsistent business data into a clean, structured, and reliable form that machines can understand and learn from.
Most companies will use a hybrid approach, meaning the data is sometimes on prem, sometime co-located, sometime in the cloud; while it would be super to have everything in one perfectly organized place, hybrid is normal and just fine.
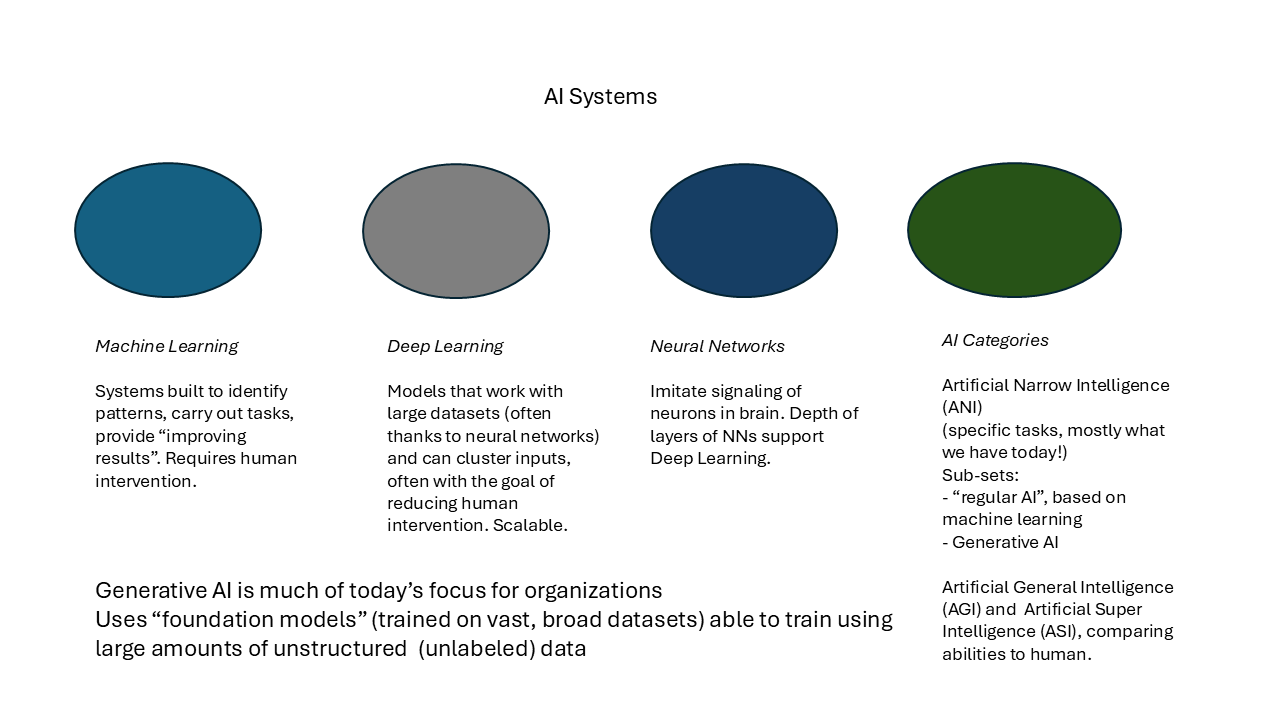
Let’s start with a challenging statistic. Often 70-80% of an organization’s data can be unstructured, aka not in table form with rows and columns. Examples of unstructured data are photos, videos, PDFs, recordings and social media feeds. More broadly, unstructured can also refer to database columns without labels.
Think of preparing data as building the runway before the plane can take off — without it, even the most advanced AI model will crash on takeoff.
Put in Risk Management terms: We want to avoid bad reports and data hallucinations, they’re just not worth it!
Here’s what this process involves at a high level:
Data Discovery, aka Audit
Identify where your data lives — ERP systems, CRMs, spreadsheets, web analytics, IoT sensors. What is unstructured versus unstructured? What about differences between different countries, legal entities or plants?
Non- text and -numerical. Are pictures, videos, PDFs, social media posts, speech/voice important data for your business?
Document what each dataset represents and who owns it.
Document between structured and unstructured data.
Data Cleaning
Fix missing values, remove duplicates, and ensure consistent formats. This can often be a lot of work and may require a phased approach. Just remember:
Bad data leads to bad output and poor predictions — it’s that simple.
Data Integration
Combine siloed data into a unified view.
Build a single source of truth (e.g., a data warehouse or data lake).
Again: might require priority-based phases.
Feature Engineering
Transform raw fields into meaningful metrics — for example, “average purchase frequency” or “days since last order.”
Governance and Security
Define data ownership, access permissions, and compliance standards (GDPR, HIPAA, etc.).
Define Requirements and Set Up Project
Of course setting the objectives is relatively do-able. Turning that discovery - or data audit – into functional requirements needs to answer some important questions, for example:
Professionally MAP your enterprise data, physically, by application, what language, etc.. This map (description and visualization) should be a shared high-level shared view of tech and management.
What are the main issues with data readiness. What did the audit reveal?
What are the organizational priorities for Machine Learning and AI?
What is a manageable PROJECT that your organization has the capability and bandwidth to carry out?
And just like most key IT projects, spend at least a third of the project budget and timing on requirements. Get the goals and timing right, identify the resources, make a plan for building internal capability (kicking out consultants), and obtain management buy-in.
In our post-Halloween blog we’ll take a closer look at
Discussion of structured versus unstructured data and why that matters!
What are the key tech requirements preparing data for the world of neural networks and LLMs? Is that different than “regular data”?
More best practices for requirements and project set-up
How can smart data in the Cloud make things better?
For now, have a spooky fun week.